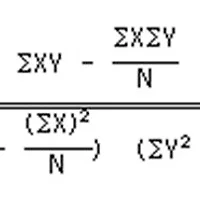DNA microarrary와 같은 실험을 통해서 얻어진 대량의 데이터를 처리하는 방법 중 하나로, 클러스터링(clustering)과 분류(classification)가 있다. DNA microarray를 사용한 데이터 처리는 언뜻 생각하기에는 영상 처리 관련 기술이 중요할 것 같지만, 실제로 영상 처리보다 통계적 패턴 처리가 데이터의 품질을 좌우한다. 클러스터링의 경우, 대상이 되는 데이터는 유전자이며, 이것을 적절하게 그룹화하는 것인데, 비슷한 유전자끼리 얼마나 잘 모을 수 있는가가 관건이 된다. 클러스터링 방식을 나눠보면, 작은 것에서부터 큰 것으로 모아가는 merge 방식과, 하나의 묶음에서 점차 잘라내가는 splitting 방식으로 구별할 수 있는데, 대표적으로 다음과 같은 클러스터링 방법이 있다.
1. Hierarchical clustering
2. k-means
3. Bayesian approaches
4. Projection techinique
여기서 Hierarchical Clustering은 비슷한 유전자끼리 모아가며 커다란 유전자 그룹을 형성해나가는 방식이며, k-means은 임의의 k 값을 중심으로, 이 값과 인접한 유전자를 모아가는 방식이다.
분류는, 유전자 발현 패턴을 사용해서 해당 유전자가 어떤 범주에 속하는지 파악하는 것이다. 즉, 미리 정의된 카테고리에 데이터를 적당하게 분배하는 것이라 할 수 있다. 분류는, 어떤 알고리즘이 주어진다고 하더라도 이것을 사용해서 바로 좋은 결과를 얻기가 힘들며, 해당 알고리즘이 실제로 데이터를 적절하게 분류하는지 조정하는 단계가 필요하다. 대표적으로, 다음과 같은 분류 방법이 있다.
1. Support Vector Machine
2. Decision Tree
3. Neural Networks
4. K-Nearest Neighbors
클러스터링은 Machine Learning 형태이며, 의도하지 않은 결과를 만들어낼 수 있다. 이에 비해 분류는 Supervisored Learning이라고도 불리는데, 입력 데이터에 대해서 언제나 의도된 결과를 출력한다. 이것은 미리 조정되어 있는 알고리즘을 사용하기 때문이다.
1. Hierarchical clustering
2. k-means
3. Bayesian approaches
4. Projection techinique
여기서 Hierarchical Clustering은 비슷한 유전자끼리 모아가며 커다란 유전자 그룹을 형성해나가는 방식이며, k-means은 임의의 k 값을 중심으로, 이 값과 인접한 유전자를 모아가는 방식이다.
분류는, 유전자 발현 패턴을 사용해서 해당 유전자가 어떤 범주에 속하는지 파악하는 것이다. 즉, 미리 정의된 카테고리에 데이터를 적당하게 분배하는 것이라 할 수 있다. 분류는, 어떤 알고리즘이 주어진다고 하더라도 이것을 사용해서 바로 좋은 결과를 얻기가 힘들며, 해당 알고리즘이 실제로 데이터를 적절하게 분류하는지 조정하는 단계가 필요하다. 대표적으로, 다음과 같은 분류 방법이 있다.
1. Support Vector Machine
2. Decision Tree
3. Neural Networks
4. K-Nearest Neighbors
클러스터링은 Machine Learning 형태이며, 의도하지 않은 결과를 만들어낼 수 있다. 이에 비해 분류는 Supervisored Learning이라고도 불리는데, 입력 데이터에 대해서 언제나 의도된 결과를 출력한다. 이것은 미리 조정되어 있는 알고리즘을 사용하기 때문이다.